Golem application fundamentals
What is a Golem application?
A Golem application is any kind of software that utilizes Golem Network's resources. It usually consists of two counterparts: a requestor agent and a provider component, which work together to deliver the functionality that the requestor needs.
In the simplest case, the provider component is a docker-like image (sometimes referred-to as "payload") running on the provider's machine. The image is run in a way that assures effective isolation of execution from the host. A single Golem application can utilize multiple such components.
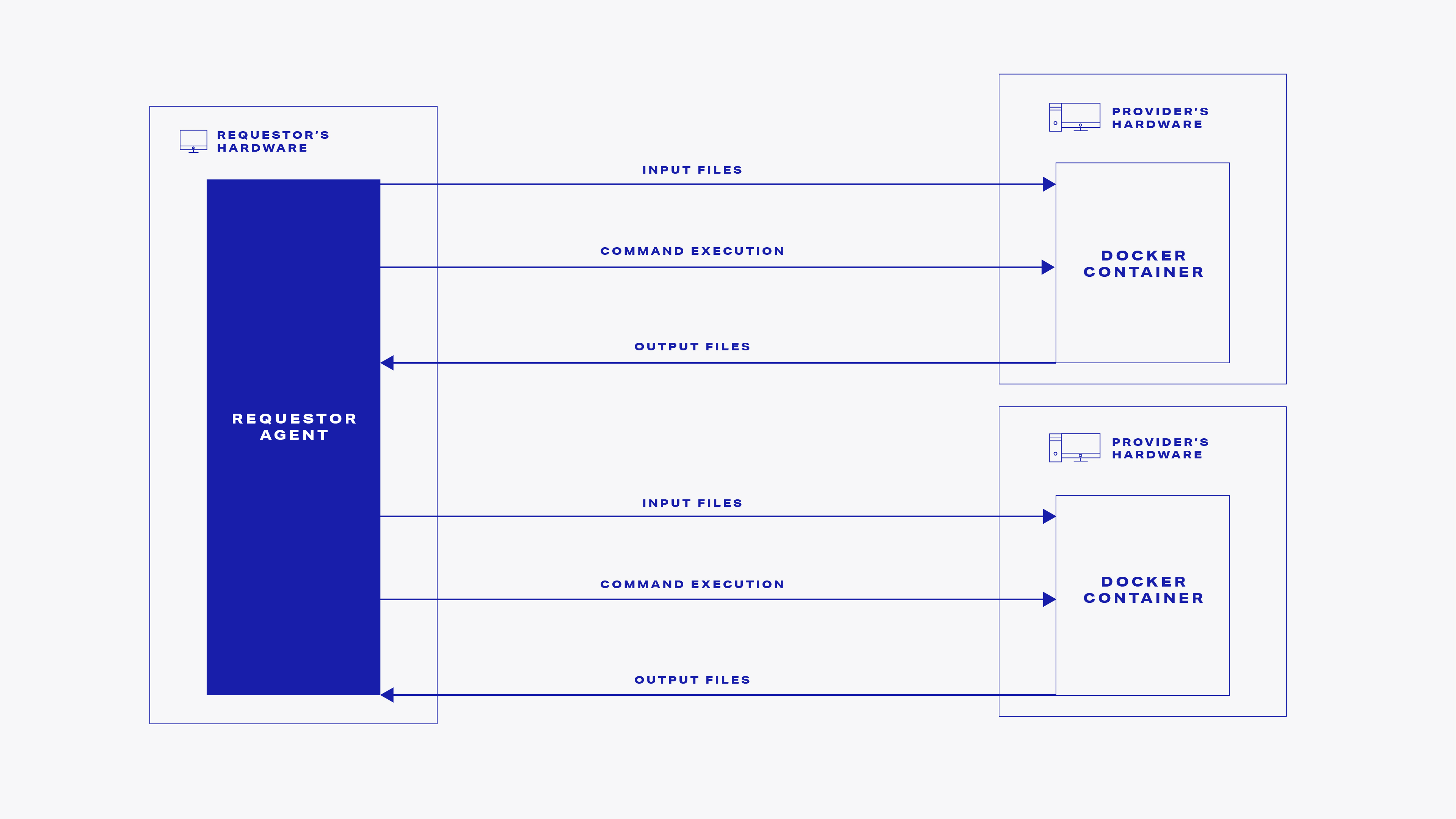
The provider payloads are orchestrated by the requestor agent, which is a piece of code talking directly to yagna via its REST API on the requestor's end.
So far, said orchestration takes the form of one of three types of actions:
- Sending input files to the provider
- Running commands on the provider and reading their output streams
- Getting output files back from the provider
Requestor agents may implement additional logic like splitting the computation into several parts for execution on providers and combining them to form the final output once all the parts are processed.
Additionally, it's the requestor's responsibility to use a specific VM image, adequate for the task at hand. In many cases such an image already exists, or can be easily created out of an existing docker image.
Custom runtime environments
Above, we've limited ourselves to the most common case, a runtime environment hosting docker-like containers. However, Golem's architecture is capable of utilizing custom runtime implementations as long as there are providers on the network, who offer the given runtime.
To learn about some additional details on how different parts of Golem work together, please have a look at:
Work generator pattern and WorkContext
Intro
Golem applications using yapapi follow a pattern where a requestor agent issues commands which are relayed to and executed on the provider side. The responses from those commands are fed back to the requestor agent, and may be processed further, according to the application logic.
In all cases where execution of those commands is required, this is instrumented using a work generator pattern, a variation of the Command design pattern. Actions to be performed are wrapped under Script objects, which are marshaled by the high-level API library. The requestor agent programmer is expected to develop code which composes those scripts and returns them via an asynchronous generator.
Basic example
Consider a simple code example of a work generator function used by the Task API:
async def worker(context: WorkContext, tasks: AsyncIterable[Task]):
async for task in tasks:
script = context.new_script()
future_result = script.run("/bin/sh", "-c", "date")
yield script
task.accept_result(result=await future_result)A worker() function is specified, which will be called by the high-level library engine for each provider, to iterate over the input tasks and send appropriate commands to the Provider. This function (representing the task-based execution model) receives:
- a
WorkContextobject used to construct the commands (common to both the Task API and the Services API), - a collection of
Taskobjects which specify individual parts of the batch process to be executed (specific to the Task API).
For each set of commands that we'd like to execute on the provider's end, the new_script() is called on the WorkContext instance to create a Script object to hold our execution script.
Then, a run() method is called on the Script instance to build a command which issues a bash statement on the remote VM. This call builds a RUN command. Note that we're saving a handle to its future result (which is an async awaitable that will be filled with the actual result later on).
A subsequent yield statement then sends the prepared script to the caller of the worker() method, which effectively passes it for execution by the provider.
Both the aforementioned run command and the yield statement return awaitable objects wrapping the results. Those Future objects can be awaited upon to obtain the response for a specific command or for the whole script respectively, which can be processed further. The worker() execution for this specific provider halts until the generated work command gets processed.
Script API
Script is a facade which exposes an API to build various commands. Some useful methods are listed below:
run(statement(, arguments))
Execute an arbitrary statement (with arguments).
The semantics of the command is specific to a specific runtime, e.g. for the VM runtime, it executes a shell command and returns results from stdout and stderr.
send_*(location, <content>)
A group of commands responsible for sending content to the runtime. These are utility methods, which conveniently allow for sending eg. local files, binary content or JSON content.
download_*(<content>, location)
A group of commands responsible for downloading content from the runtime. As with send_*(), these are utility methods which allow for convenient transfer and conversion of remote content into local files, bytes or JSON objects.
Was this helpful?